
Ein Gespenst geht immer noch um in der Welt der Datenwissenschaften (Data Science) – das Gespenst der Datenschutz-Grundverordnung. So hört man vielerorts mal wieder, dass viele Unternehmen in weiser Vorausschau vor dem Damoklesschwert des DSGVO-Bußgeldes ihre segensreichen Data Science-Anwendungen erheblich einschränken, gar darauf verzichten. Aber muss das wirklich sein? Was steckt eigentlich hinter dem neuen Trend-Schlagwort „Data Science“? Wo verlaufen die Grenzen der Zulässigkeit und gefährdet Europa seinen Data-Science-Standort?
Der Inhalt im Überblick
- Was bedeutet die Sammelbezeichnung Data Science?
- Die Werkzeuge des Data Scientist – Supervised und Unsupervised
- Data Architect und Data Engineer – Jedem Anfang wohnt ein Zauber inne!
- Der Datenschutz – Ein Elefant im Raum?
- Data Science und Datenschutz – Für immer und ewig gebunden?
- Bremst der Datenschutz?
Was bedeutet die Sammelbezeichnung Data Science?
Da die DSGVO einen technikneutralen Ansatz verfolgt und für derartige Vorhaben keine speziellen Regelungen geschaffen wurden, bedarf es zunächst einer kleinen Begriffserläuterung.
Der Begriff „Big Data“ hat sich im Volksmund etabliert und bezeichnet eine enorme Sammlung von Daten, die nicht mehr mit dem traditionellen Datenbanksystem zu verarbeiten sind.
Daten lediglich in Unmengen zu sammeln, ist aber etwas gedanken- und perspektivlos. Schließlich will man im Ergebnis aus diesen enormen und unstrukturierten Datenmengen, Informationen und unter Umständen sogar ökonomisch verwertbare Erkenntnisse gewinnen, die anschließend zu mehr Effizienz und Produktivität führen können. Genau da kommt der oder die Data Scientist ins Spiel!
Bei Data Science geht es um Wissen!
Konkreter und wohl mathematisch korrekt ausgedrückt, um die Extraktion von Wissen aus Daten. Dieses Wissen ergibt sich aus Korrelationen zwischen Variablen in einem Datensatz.
Vereinfacht ausgedrückt: Es geht um Zusammenhänge oder Abhängigkeiten zwischen den Daten in einem Datensatz. Diese Zusammenhänge innerhalb eines Datensatzes können dabei hilfreich sein, Prognosen oder Schätzungen für ein bestimmtes Ereignis oder Ergebnis zu treffen.
Windeln, Männer und Bier? Finde die Korrelation!
Um das Ganze mal plastisch darzustellen, stellen Sie sich hierzu einen „schwer angestrengten“ Vater zur Abendzeit in einem Supermarkt vor. Dieser „schwerermüdete“ und vom Leben geplagte Vater sucht nach Babywindeln für sein Neugeborenes. Während er noch schwermütig an die alten Zeiten als Junggeselle zurückblickt, erkennt er im Regal direkt links neben den Windeln eine Packung Beef Jerky und rechts daneben – wer hätte es gedacht – Bier!
Die unbekannte Instanz zwischen all diesen Datenpunkten? Müde Väter, die zur Abendstunde nach Windeln suchen, mögen Bier und gedörrtes Fleisch. Die Korrelation zwischen Bier und Windeln brachte dem Supermarkt-Riesen Walmart ca. 25 % mehr Umsatz ein.
Infrastruktur, Daten und Mathe
Um nun Informationen und Erkenntnisse aus diesen unstrukturierten Datenmengen zu gewinnen, bedarf es im Wesentlichen:
- Einer performanten Daten-Infrastruktur
- und damit einhergehend Daten mit einer “guten“ Datenqualität
- und spezielle Daten-Modellierungstechniken.
Dieser gesamte und aus diversen Prozessen bestehende – im Besonderen mathematische Extraktionsprozesse – Vorgang wird unter dem Sammelbegriff Data Science gefasst. Data Science ist in gewisser Weise der Bereich, der alles umfasst, was mit Datenbereinigung, Datenaufbereitung, „vertiefte“ Datenanalyse und Datenvisualisierung zu tun hat.
Hierbei bedient sich der Data Scientist an hochmathematischen Methoden und Annäherungsmodellen. Über die übliche Praxis eines Data Analysten hinaus, nutzen Data Scientists unteranderem Analysemethoden wie das „Maschinelle Lernen“ (auch oft unter dem Schlagwort „Künstliche Intelligenz“ bei diversen Talk-Shows anzutreffen).
Die Werkzeuge des Data Scientist – Supervised und Unsupervised
Data Scientists nutzen dabei im Wesentlichen zwei Verfahren: Das sogenannte Supervised-Verfahren und das sog. Unsupervised-Verfahren. Insbesondere diese Verfahrensarten sind relevant zur Bestimmung etwaiger datenschutzrechtlicher Probleme.
Beim Supervised-Verfahren (Überwachtes Verfahren) wird eine Hypothese festgelegt und damit ein Zweck (bspw. Kreditwürdigkeit von Max Mustermann oder von Gruppe X) im Vorfeld konkret bestimmt. So gibt es bereits aufbereitete und validierte Daten, die als Lerndatensatz dienen, um zuvor festgelegte Hypothesen zu falsifizieren oder verifizieren. Hierbei beweist der/die Data Scientist mit bereits vorhandenen Erfahrungssätzen, ob die Hypothese zutrifft oder nicht. Anhand dieser Methode können bspw. Banken mit ihren Erfahrungsdaten feststellen, ob ein Kreditnehmer kreditwürdig ist.
Beim Unsupervised-Verfahren (Unüberwachtes Verfahren) existiert meist weder ein Lerndatensatz noch eine zu überprüfende Hypothese. In diesem Verfahren agiert der Data Scientist ergebnisoffen und hofft auf zufällige Zusammenhänge und Abhängigkeiten zu stoßen. Dabei werden Datensätze durchforstet, ohne zuvor ein Ziel bzw. einen Zweck festzusetzen. Der Fokus besteht hierbei darin, nach einer unbekannten Instanz zu „wühlen“. Vereinfacht und mathematisch wohl unkorrekt ausgedrückt: Müdigkeit + Vaterdasein = Scheinbar hohes Verlangen nach „Männlichkeit“, respektive Bier.
Wir ersparen Ihnen an dieser Stelle weitere Einzelheiten, da wir uns sonst mit folgenden Formeln (Hauptkomponentenanalyse) auseinandersetzen müssten:
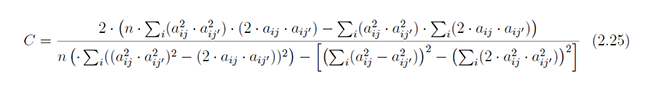
Data Architect und Data Engineer – Jedem Anfang wohnt ein Zauber inne!
Keine Frage, Data Science ist die unangefochtene Königsdisziplin. Sozusagen das mathematische Hochreck unter den Datenanwendungen.
Um das Datenschutz-Pferd aber nicht von hinten aufzuzäumen, muss man notwendigerweise zunächst einen Blick zurück auf den Startpunkt einer Datenplattform werfen. Denn noch bevor der Data Scientist seine hochmathematischen Modelle wie bspw. die Hauptkomponentenanalyse oder das Clustering anwerfen kann, muss im Idealfall ein Data Architect und/oder ein Data Engineer die Voraussetzungen hierfür schaffen.
Sowohl der Data Architect als auch der Data Engineer sind die Konstrukteure und Schnittstellen-Ermöglicher einer Datenplattform. Sie bilden im Idealfall den Startpunkt und setzen die Rahmenbedingungen fest.
Der Data Engineer im Besonderen gilt als technischer Datenaufbereiter und arbeitet dem Data Scientist zu. Er/Sie entwickelt, pflegt, überwacht Daten Ein- und Ausgänge, integriert und verwaltet große Datenmengen aus verschiedenen Datenquellen. Er/Sie kümmert sich so gesehen, um die Erstellung einer funktionierenden Daten-Infrastruktur für die weitere Verwendung des Data Scientists.
Damit legen der Data Architect und der Data Engineer nicht nur den Grundstein für eine performante Daten-Infrastruktur, sondern auch für den so oft gescholtenen Datenschutz. In ihrer Verantwortung stehen somit die gesamten technischen und organisatorischen Maßnahmen, wie bspw. das Identitäts- und Zugriffsmanagement, aber auch die Vornahme einer grundlegenden datenschutzrechtlichen Vorabkontrolle:
Welche eingespeisten Daten weisen einen Personenbezug auf? Welche Daten könnten durch die Zusammenführung der Datenbanken oder durch die Analyse des Data Scientist einen Personenbezug aufweisen? Genügen ggf. anonyme Daten für die Durchführung des Projekts? Liegen für die einzelnen Datenverarbeitungsschritte und für die weitere Verwendung alle Rechtsgrundlagen und Informationspflichten vor? Bin ich in der Lage etwaigen Löschverpflichtungen nachzukommen?
Wer bereits hier fahrlässig mit der Datensicherheit und dem Datenschutz umgeht, lässt dem Data Scientist und allen nachfolgenden Verwendern in der Datennutzungskette keine wirkliche Chance mehr sich datenschutzkonform zu verhalten bzw. die Früchte der Erkenntnisse rechtskonform zu nutzen.
Ergo: Wer Data Science sagt, muss auch Data Engineer und Data Architekt sagen. Beachten Sie in Ihren Data-Science-Projekten daher immer den sakrosankten Privacy by Design-Ansatz.
Der Datenschutz – Ein Elefant im Raum?
Aus der datenschutzrechtlicher Brille betrachtet, gibt es bei Data-Science-Projekten diverse Problemefelder, an die es zu denken gilt. Exemplarisch werfen wir einen Blick auf den
- Personenbezug,
- die Anonymisierung und
- den Zweckbindungsgrundsatz.
Datenschutz bei anonymen Daten
Bei Daten, die keinen Personenbezug aufweisen (anonyme Daten), fehlt es an einem Eingriff in das informationelle Selbstbestimmungsrecht. Bei solchen Daten ist es dem Data Scientist auch mit Zusatzwissen nicht möglich, eine Person zu identifizieren. Gegen eine derartige Datenverarbeitung können deshalb auch keine datenschutzrechtlichen Bedenken bestehen. Data-Science-Projekte unterliegen dann auch keinen Beschränkungen seitens des Datenschutzrechts.
Aber Achtung: Ein kleiner feiner Unterschied besteht immer noch zwischen einer faktisch anonymisierten Datenerhebung (Keine Geltung der DSGVO) und einer nachträglichen Anonymisierung. Bei einer nachträglichen Anonymisierung werden personenbezogene Daten zunächst – wie sonst üblich – erhoben und erst im Nachgang anonymisiert. Bis zu diesem Anonymisierungsvorgang gelten weiterhin die Schutzbestimmungen der DSGVO, respektive die Notwendigkeit einer Rechtsgrundlage und etwaige Informationspflichten gegenüber dem Betroffenen.
Risikoabwägung hinsichtlich der Anonymisierung
Das was der Volksmund als Anonymisierung begreift, ist leider nicht immer das Gleiche was die DSGVO im Sinn hatte. Oft ist daher dem Data Scientist nicht klar, ob die ihm vorliegenden Daten wirklich anonymisiert wurden oder lediglich pseudonymisiert vorliegen. Denn bei pseudonymen (personenbezogenen) Daten gilt auch weiterhin die „volle Bandbreite“ der DSGVO Regulierung.
Der Anonymisierungsvorgang ist daher, insbesondere bei einem vermeintlich harmlosen Datenabgleich oder der Zusammenführung von Datenbanken, aber auch bei den weitaus komplexeren Datenreduktionspraktiken des Data Scientist, immer genau zu beleuchten.
Eine Risikoabwägung im Hinblick auf eine Reidentifizierung einer Person ist jedem guten Data-Science-Projekt demgemäß anzuraten. Dabei zu berücksichtigen sind insbesondere die – rechtlich zulässigen – Identifizierungsmöglichkeiten, der Reidentifizierungsaufwand sowie das Identifizierungsinteresse des Data Scientists. Eine amüsante Faustregel besagt: Wenn sie den Personenbezug wieder herstellen können, dann hatten sie es auch nie wirklich mit anonymisierten Daten zu tun gehabt.
Da durch das Entfernen sämtlicher dazu geeigneter Informationen oftmals auch der Aussagewert der Datensätze drastisch reduziert wird, wird in diesem Bereich in Zukunft vermehrt auf synthetische Daten gesetzt. Hinter dem Begriff steht ein durch KI aus den Originaldaten erstellter künstlicher Datensatz, der sehr ähnliche statistischen Informationen und Strukturen aufweist. Ziel dabei ist es, einen von der Aussagekraft äquivalenten Datensatz zu erstellen, der nicht auf die ursprünglichen Werte zurückgeführt werden kann und somit auch kein Risiko einer Reidentifikation mehr aufweist.
Zweckbindungsgrundsatz und die Einwilligung als Rechtsgrundlage
Der Zweckbindungsgrundsatz ist das Herzstück unseres europäischen Datenschutzverständnisses. Diesem Prinzip zur Folge dürfen Daten grundsätzlich nur für den Zweck verwendet werden, für den sie zu Beginn erhoben wurden. Eine Ausnahme macht die DSGVO nur für wissenschaftliche oder historische Forschungszwecke und statistische Zwecke gem. Art. 5 Abs. lit. b) DSGVO, EG 159, EG 160, EG 162.
Relevant wird der Zweckbindungsgrundsatz bei der Einholung einer Einwilligung als Rechtsgrundlage einer Datenverarbeitung. Insbesondere die Verarbeitung von personenbezogenen Gesundheitsdaten verlangen eine ausdrückliche Einwilligung des Betroffenen (Art. 9 Abs. 2 lit. a DSGVO).
Für eine wirksame Einwilligung sind die Betroffenen über verschiedene Rechte und über die wesentlichen Verwendungen und Prozesse der vorgesehenen Datenverarbeitung zu informieren. Denn nur wer einigermaßen abschätzen kann, welche Folgen die Erteilung einer Einwilligung für ihn haben wird, kann selbstbestimmt darüber entscheiden, ob er dieser Datenverarbeitung zustimmt. Der Einwilligende muss demnach vorher konkret über die Folgen und die Tragweite seiner Zustimmung, d.h. über die beabsichtigte Verwendung seiner Daten (Zweck, Datenkategorie, Empfängerkreis, verantwortliche Stelle etc.) aufgeklärt werden.
Beispiel: Werden die Erkenntnisse des Data Scientist dazu genutzt, um bspw. einem Unternehmen betriebswirtschaftliche oder personelle Vorschläge zu unterbreiten, sind die Beschäftigten, deren personenbezogene Daten in diesem Data-Science-Kontext verarbeitet wurden, über diese Verwendung und deren Folgen auch zu informieren. Führt die Persönlichkeitsanalyse des Data Scientist dazu, dass bspw. ein Bewerber im Nachgang abgelehnt oder ein Beschäftigter nicht befördert wird, muss dieser darüber informiert worden sein.
Wachsweiche Formulierungen wie „Ressourcen-Planung“ oder “Effizienzsteigerungsmaßnahmen“ genügen den rechtlich verbrieften Ansprüchen der Zweckbindung nicht!
Data Science und Datenschutz – Für immer und ewig gebunden?
Damit bindet der Zweckbindungsgrundsatz der DSGVO – streng dogmatisch betrachtet – den Data Scientist oftmals an einen vor der Datenerhebung festgelegten Zweck!
Wesentlich unproblematischer wird es für den Data Scientist, wenn er mit dem sogenannten Supervised-Verfahren arbeitet. Im sogenannten Supervised-Verfahren (Überwachtes Verfahren) ist die Hypothese festgelegt und damit der Zweck im Vorfeld konkreter zu bestimmen. Hierbei beweist der Data Scientist mit bereits vorhandenen Erfahrungssätzen, ob die Hypothese zutrifft oder nicht.
Beim Unsupervised-Verfahren (Unüberwachtes Vefahren) ist die Lage wesentlich komplizierter. Hier arbeitet der Data Scientist ohne ein Ziel vor Augen zu haben, also ergebnisoffen. In diesem Verfahren ist also eine konkrete Zwecksetzung, mangels Ausgangs-Hypothese, nur schwerlich zu bewerkstelligen, sodass hierbei höchste Vorsicht geboten ist.
Denn generalisierende und zu abstrakte Zweckbestimmungen (sog. blanket consents) können zur Unwirksamkeit einer Einwilligung führen. Die Grenze zwischen einer zu weiten Einwilligungserklärung und einer rechtssicheren, aber dennoch weit formulierten Einwilligungserklärung sind umstritten und sollten daher immer im Einzelfall beurteilt werden.
Um einen künftigen Data Science-Standort in Deutschland/Europa nicht zu gefährden, müsste der Gesetzgeber hier vermutlich nachjustieren und spezielle Regelungen für diese Verfahren und Modelle schaffen. Ansonsten bliebe, aufgrund der mangelnden Rechtssicherheit im sog. Unsupervised- Verfahren, nur noch die Anonymisierung der Daten.
Bremst der Datenschutz?
Sicherlich! Denn der Datenschutz dient als Ermächtigungswerkzeug des Betroffenen zur Verwirklichung seines Selbstbestimmungsrechts und wurde ins Leben gerufen, um etwaige Machtasymmetrien zu regulieren (Art. 1 Absatz 2 DSGVO). Falsch ist auch nicht, dass Anonymisierungsverfahren bei mehrschichtigen Datenbanken und unzähligen Pfaden im Data Warehouse eines Unternehmens zeitaufwendig sein können.
Aber. Bei Daten ohne Personenbezug oder anonym erhobenen Daten greifen die Schutzbestimmungen der DSGVO erst gar nicht. Das gleiche gilt für reine Maschinendaten. Hier ist die Sorge des Data Scientists also vollkommen unbegründet! Zeitgleich soll mit der Einführung des Data Governance Acts eine breitere Weiterverwendung geschützter Daten des öffentlichen Sektors ermöglicht werden. Öffentliche Datenplattformen wie die der Wissenschaftsstadt Darmstadt bezeugen, dass der Datenschutz nicht überall eine Bremse darstellen muss.
Nein. Data-Science-Projekte scheitern nicht (primär) am Datenschutz, sondern – um es mal makroökonomisch einzuordnen – zuvörderst am MINT-Fachkräftemangel, am Investitionsstau im privaten, sowie im öffentlichen Sektor und damit einhergehend an nicht-performanten IT-Infrastrukturen und letztlich an den viel zu hohen Erwartungen an den Data Scientist. Sinnbild hierfür ist die im Jahre 2021 verlautbarte Datenstrategie der Bundesregierung. Diese versprach die Etablierung von Datenlaboren und die Integration von Chief Data Scientists in allen Bundesministerien. Zum Chief Data Scientist gehören aber genauso viele Chief Data Architects und Chief Data Engineers. Denn mit „schlechten“ Daten und einer maroden Infrastruktur kann auch der beste Chief Data Scientist nichts Produktives anstellen.






Sehr richtige Beobachtung. Hinter dem Data Scientist steht eine ganze Infrastruktur – ohne die er nicht gar nicht wirken könnte. Ins Feld führen sollte man auch die Bedeutsamkeit der Datenqualität. Vielen Dank für den Artikel.
Läuft der Datensparsamkeitsgrundsatz der DSGVO dem nicht zu wider?
Der Grundsatz der Datensparsamkeit folgt aus dem alten BDSG – § 3a Satz 1 BDSG und gilt seit dem 25.05.2018 nicht mehr. Von da an gilt der sog. Datenminimierungsgrundsatz aus Art. 5 Absatz 1 lit. c DSGVO. Dieser lässt – dem Wortlaut nach – zumindest mehr Spielraum zwecks Data Science – Praktiken. Im Unsupervised Verfahren (ML) verbleibt aber immer ein Restrisiko, aufgrund der fehlenden Zweckbindung. Darauf können wir gerne in einem gesonderten Artikel vertieft eingehen.
In diesem Kontext verweise ich aber sehr gerne auf die Leitlinie für Transparenz der Art.-29-Datenschutzgruppe auf Seite 40, welche im Kontext von Art. 11 DSGVO auf die Pseudonymisierung als Möglichkeit zur Durchsetzung des Datenminimierungs-Grundsatzes hingewiesen hat.
Unter WP 260 rev.01 hier zu finden: https://www.datenschutzkonferenz-online.de/wp29-leitlinien.html
VG Nima Oshnooei
Wann genau kann man als interessierter Leser mit diesem -von Ihnen angekündigten- Artikel rechnen?
Beste Grüße und herzlichen Dank.